*Sequential Model
- 문장을 예로 들면 문장의 길이는 가변적이고 중간이 생략될 수 있음
- 이러한 문제들 때문에 sequential한 입력에 대해 모델링하는것이 어렵다
- transformer를 통해 해결할 수 있음
*Transformer
- Transformer is the first sequence transduction model based entirely on attention

- encoder , decoder 구조

encoder - decoder - Encoder의 Self-Attention
- n개의 단어를 한번에 인코딩할 수 있음
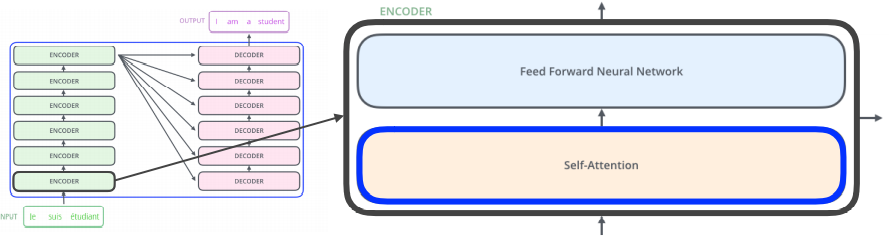
- 각 단어를 z에 모두 인코딩함

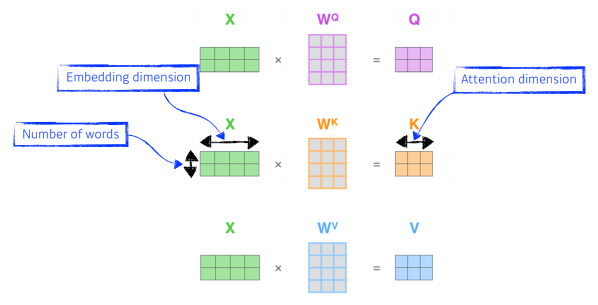
- 3가지 종류의 벡터를 만든다 (Quries, Keys, Values) : 한 단어마다 3개의 벡터를 만들고 임베딩함

Embedding - thinking 단어에 대한 score 벡터를 계산할때 내가 인코딩을 하고자하는 모든 단어에 대한 key벡터를 내적함
=>i 번째 단어가 나머지 n-1개의 단어와 유사도가 있는지 score를 계산
- Score를 normalization해줌. key벡터 차원의 sqrt를 취해서 나눠준다

attention weight - 위에서 구한 attention weight과 value벡터와 weighted sum을 한것이 최종적으로 thinking의 인코딩된 벡터

- 위 과정들을 행렬로 나타냄

- RNN과 비교해보면?
RNN은 시퀀스가 100만개면 오래걸리더라도 100만번을 수행하면 결국 100만개의 단어를 처리하는 무언가가 될 수 있다. - Transformer는?
n개의 단어가 주어지면 n x n 어떤 attention map을 만들어야하므로 n^2에 비례하는 computation이 필요함.
따라서 length가 길어지면 한계가 있지만, 훨씬더 많은걸 표현할 수 있고, flexible 하다.
- n개의 단어를 한번에 인코딩할 수 있음
- Multi-head attention (MHA)
- attention을 여러번 수행. query, key ,value 를 여러개 만든다.

- 하나의 임베딩된 벡터가 있으면 8개의 인코딩된 결과가 나온다. 실제 8개의 헤드를 사용

- 고려해야될점? - 입력과 출력의 차원을 맞춰줘야함. 즉, 임베딩된 차원과 인코딩된 셀프어텐션으로 나온 벡터의 차원이 같아야함.
- ex) 10차원짜리 8개가 있으면 80차원 인코딩된 벡터인데, 이를 80x10 행렬곱을 취해서 10차원으로 만들어줌

w0 = linear map - Summary

summary - why do we need positional encoding?
- 일종의 bias
- transformer에서 n개의 단어를 sequential하게 넣어줬다고 치지만 sequential한 정보가 이 안에 포함되어 있지 않다. -> 주어진 입력에 어떤값을 더한다

positional encoding - example

4-dimensional encoding - 전체 구조

- attention을 여러번 수행. query, key ,value 를 여러개 만든다.
*Visoin Transformer
- NLP에서 활용하던 transformer를 vision에서도 활용하게 됨
- image를 subpatch로 나누어 입력으로 넣어준다 ->역시 positional encoding 필요

'부스트캠프 AI Tech > [Week2] Deep Learning basic' 카테고리의 다른 글
| [Week2] DL Basic - Generative Models [Day5] (0) | 2021.08.13 |
|---|---|
| [Week2] DL Basic - RNN [Day4] (0) | 2021.08.12 |
| [Week2] DL Basic - CNN [Day3] (0) | 2021.08.11 |
| [Week2] DL Basic - Optimization [Day2] (0) | 2021.08.10 |
| [Week2] DL Basic - MLP(Multi-Layer-Perceptron) [Day1] (0) | 2021.08.09 |



