*Detectron2 이란?
Detectron2는 Facebook AI Research(FAIR)에서 개발한 Pytorch 기반의 Object Detection, Segmentation 라이브러리이다. MMDetection과 마찬가지로 모듈식으로 작동한다.

*Run a pre-trained detectron2 model
https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5#scrollTo=7unkuuiqLdqd
1) COCO 형식의 이미지 준비
2) Config와 DefaultPredictor 생성, Inference 하기

3) 결과 시각화하기

*Use Builtin Datasets
- 데이터셋들은 DETECTRON2_DATASETS 환경 변수에 명시된 디렉토리()에 존재하는 것으로 가정한다. Detectron2는 기본적으로 COCO, LVIS, Cityscapes, VOC20 데이터셋(=builtin datasets)을 지원한다.
- Custom dataset의 경우 DatasetCatalog, MetadataCatalog라는 클래스를 이용해 사용하는 것 같다.
*Extend Detectron2's Defaults
- Detectron2는 두 종류의 인터페이스를 제공함.
- yaml 파일로부터 생성된 config를 이용하는 함수와 클래스
model = build_model(cfg) - 명시적으로 아규먼트가 잘 정의된 함수와 클래스
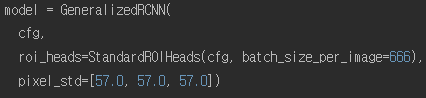
- @configurable 데코레이터와 함께 실행되는 몇몇 함수와 클래스
- yaml 파일로부터 생성된 config를 이용하는 함수와 클래스
*Use Custom Datasets
- 이번 단계에선 위에서 언급한 데이터셋 API들 (DatasetCatalog, MetadataCatalog)가 어떻게 작동하고, 커스텀 데이터셋을 추가하고자 할 때 이들을 어떻게 이용할 수 있는지 알아본다.
- Detectron2의 dataloader를 재사용하면서 새로운 커스텀 데이터셋을 사용하고자 할 때는 다음과 같이 해야함.
- 데이터셋 등록(Register)
- (옵션) 데이터셋을 위한 metadata 등록
* Register a Dataset
- Detectron2가 데이터셋을 어떻게 획득하는지 알게 하기 위해, 유저는 dataset의 아이템을 리턴하는 함수를 만들고 이 함수를 Detectron2에게 알려야 한다.
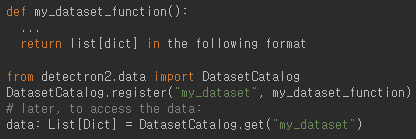
- 이때, my_dataset_function은 호출될 때마다 같은 순서의 같은 데이터를 list [dict] 형태로 리턴해야 한다. 그리고 dict는 아래의 형식을 따라야 한다.
- Detectron2의 standard dataset dict를 따를 것
- 임의의 포맷을 따르는 dict
- 결국 standard dict, 임의의 dict 모두 상관없음. standard dict를 따를 경우에는 Detectron2의 많은 builtin 피쳐들을 이용할 수 있음
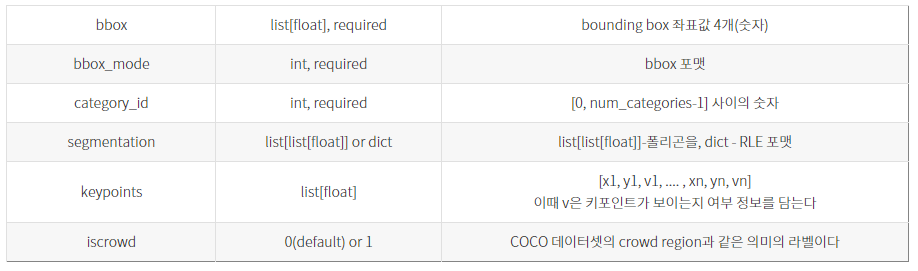
- Standard Dataset Dicts : Dict는 한 이미지에 대한 정보를 담고 있고, Object detection의 다음과 같은 필드를 필요로 함.
- file_name / height / width / image_id / annotations
- annotations은 다음과 같은 key를 갖음
*Metadata for Datasets
- 각각의 데이터셋은 MetadataCatalog.get(dataset_name).some_metadata로 접근 가능한 metadata와 관련되어 있다.
- Metadata는 key-value 형식으로, 전체 데이터셋이 공유하는 정보를 담고 있다.
- 그리고 이것은 데이터셋에 어떤 데이터가 들어있을지 해석하기 위해 쓰인다. (ex. class 명, class 색, 파일 루트 디렉토리) 이러한 정보는 평가, 로깅, 시각화, augmentation 등에 유용하게 쓰인다.
- DatasetCatalog.register를 통해 데이터셋을 등록했다면, MetadataCatalog.get(dataset_name).some_key = some_value를 통해 메타 데이터를 등록할 수 있다.
from detectron2.data import MetadataCatalog MetadataCatalog.get("my_dataset").thing_classes = ["person", "dog"]
*Register a COCO Format Dataset
- 이미 COCO 포맷으로 데이터가 준비되어 있다면, 데이터셋과 메타 데이터를 쉽게 등록할 수 있다.
from detectron2.data.datasets import register_coco_instances register_coco_instances("my_dataset", {}, "json_annotation.json", "path/to/image/dir") - 데이터셋이 COCO 포맷이지만 추가적인 처리 혹은 annotation의 커스터마이징이 필요하다면 load_coco_json 함수를 쓰는 것이 더 좋다.
*Update the Config for New Datasets
- 데이터셋을 등록한 후에는 데이터셋 이름으로 데이터셋을 이용할 수 있다. (위의 예시 같은 경우 my_dataset이 데이터셋의 이름이다.) 새로운 데이터셋에 대해서는 다음과 같이 config를 변경할 수 있다.

*Dataloader
- Dataloader는 모델에게 데이터를 제공하기 위한 요소이다. Dataloader는 보통 데이터셋으로부터 날 것의 데이터를 가져와 모델이 필요로 하는 형식으로 처리하는 역할을 한다.
*How the Existing Dataloader Works
Detectron2는 이미 내재된 데이터 로딩 파이프라인을 가지고 있다. build_detection_(train, test)_loader는 다음과 같이 동작한다.1. 등록된 데이터셋의 이름을 가지고 list [dict] 형태의 데이터셋 아이템을 경량 형식으로 로드한다. 이 데이터셋의 아이템들은 곧바로 모델에서 쓰일 수 없다. (ex. 메모리에 이미지가 로드되지 않음, random augmentation이 적용되지 않음) 2. list 내 각각의 dict는 "mapper" 함수에 의해 매핑된다. 유저들은 이 매핑 함수를 build_detection_(train, test)_loader의 mapper 아규먼트를 통해 커스터마이징 할 수 있다. 디폴트는 Datasetmapper이다. 이때 mapper의 역할은 경량 형식의 데이터셋 아이템을 모델이 사용할 수 있는 포맷으로 바꾸는 것이다. (이미지를 불러와서, random augmentation을 적용하고 torch Tensor로 변환하는 모든 과정 포함) 만약 데이터에 custom transformation을 가하고 싶다면 custom mapper 사용하면 된다.
*Write a Custom Dataloader
custom data loading을 위해서는 build_detection_(train, test)_loader(mapper =) 코드를 통해 다른 mapper를 사용해야 한다. 예를 들어 만약 학습 시 모든 이미지를 고정된 사이즈로 리사이즈하고 싶다면 다음과 같은 코드를 사용하면 된다.
import detectron2.data.transforms as T
from detectron2.data import DatasetMapper # the default mapper
dataloader = build_detection_train_loader(cfg,
mapper=DatasetMapper(cfg, is_train=True, augmentations=[
T.Resize((800, 800)) ]))
# use this dataloader instead of the default
*Use a Custom Dataloader
DefaultTrainer를 사용한다면 build_detection_(train, test)_loader 메서드를 오버라이드, 우리만의 dataloader를 만들 수 있다.
*Data Augmentation
이 튜토리얼은 새로운 data loader를 작성할 때 어떻게 augmentation을 이용할 수 있을지에 포커싱 되어 있다. 만약 Detectron2의 디폴트 data loader를 사용한다면, 그것은 이미 사용자가 지정한 custom augmentation으로의 확장을 지원한다. (바로 위에서 서술한 내용!)
*Basic Usage
from detectron2.data import transforms as T
# Define a sequence of augmentations:
augs = T.AugmentationList([
T.RandomBrightness(0.9, 1.1),
T.RandomFlip(prob=0.5),
T.RandomCrop("absolute", (640, 640)) ])
# type: T.Augmentation
# Define the augmentation input ("image" required, others optional):
input = T.AugInput(image, boxes=boxes, sem_seg=sem_seg)
# Apply the augmentation:
transform = augs(input) # type: T.Transform
image_transformed = input.image # new image
sem_seg_transformed = input.sem_seg # new semantic segmentation
# For any extra data that needs to be augmented together, use transform, e.g.:
image2_transformed = transform.apply_image(image2)
polygons_transformed = transform.apply_polygons(polygons)- 여기에 쓰인 3가지 기본 개념은 다음과 같다.
- # T.AugInput
- T.Augmentation에서 필요한에서 필요한 input을 저장한다.
- # T.Augmentation
- input을 어떻게 수정할지를 정하는 정책(policy)을 정의한다.
- # T.Transform
- 데이터를 변형하는 실제 오퍼레이션을 수행한다. apply_image, apply_coords와 같이 데이터 타입에 따라 어떻게 transform 할지 정의한다.
*Use Models - https://detectron2.readthedocs.io/en/latest/tutorials/models.html
Build Models from Yacs Config
- yacs config로부터 모델을 빌드할 때는 build_model, build_backbone, build_roi_heads 함수를 이용할 수 있다.
from detectron2.modeling import build_model model = build_model(cfg) # returns a torch.nn.Module - build_model은 랜덤한 웨이트로 채워진 모델 구조를 리턴한다.
*Load/Save a checkpoint
from detectron2.checkpoint import DetectionCheckpointer
DetectionCheckpointer(model).load(file_path_or_url) # load a file, usually from cfg.MODEL.WEIGHTS
checkpointer = DetectionCheckpointer(model, save_dir="output")
checkpointer.save("model_999") # save to output/model_999.pth- Detectron2의 checkpointe는 pytorch의 .pth 포맷, model zoo의 pkl 포맷을 인식한다.
'부스트캠프 AI Tech > [Week9] Object Detection (1)' 카테고리의 다른 글
| [Week9] Object Detection - EfficientDet [Day3] (0) | 2021.09.29 |
|---|---|
| [Week9] Object Detection - 1 stage detector [Day3] (0) | 2021.09.29 |
| [Week9] Object Detection - Neck [Day2] (0) | 2021.09.28 |
| [Week9] Object Detection - library [Day2] (0) | 2021.09.28 |



